
spark-tts
commited on
Commit
·
eb27189
1
Parent(s):
fddaaf5
update readme
Browse files- .gitignore +1 -0
- README.md +58 -1
- example/infer.sh +1 -1
- src/figures/gradio_TTS.png +0 -0
- src/figures/gradio_control.png +0 -0
- src/figures/infer_control.png +0 -0
- src/figures/infer_voice_cloning.png +0 -0
.gitignore
CHANGED
|
@@ -27,6 +27,7 @@ share/python-wheels/
|
|
| 27 |
.installed.cfg
|
| 28 |
*.egg
|
| 29 |
MANIFEST
|
|
|
|
| 30 |
|
| 31 |
# PyInstaller
|
| 32 |
# Usually these files are written by a python script from a template
|
|
|
|
| 27 |
.installed.cfg
|
| 28 |
*.egg
|
| 29 |
MANIFEST
|
| 30 |
+
webui_test.py
|
| 31 |
|
| 32 |
# PyInstaller
|
| 33 |
# Usually these files are written by a python script from a template
|
README.md
CHANGED
|
@@ -30,6 +30,26 @@ Spark-TTS is an advanced text-to-speech system that uses the power of large lang
|
|
| 30 |
- **Simplicity and Efficiency**: Built entirely on Qwen2.5, Spark-TTS eliminates the need for additional generation models like flow matching. Instead of relying on separate models to generate acoustic features, it directly reconstructs audio from the code predicted by the LLM. This approach streamlines the process, improving efficiency and reducing complexity.
|
| 31 |
- **High-Quality Voice Cloning**: Supports zero-shot voice cloning, which means it can replicate a speaker's voice even without specific training data for that voice. This is ideal for cross-lingual and code-switching scenarios, allowing for seamless transitions between languages and voices without requiring separate training for each one.
|
| 32 |
- **Bilingual Support**: Supports both Chinese and English, and is capable of zero-shot voice cloning for cross-lingual and code-switching scenarios, enabling the model to synthesize speech in multiple languages with high naturalness and accuracy.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
|
| 34 |
## Install
|
| 35 |
**Clone and Install**
|
|
@@ -53,7 +73,22 @@ pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --tru
|
|
| 53 |
|
| 54 |
**Model Download**
|
| 55 |
|
| 56 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
|
| 58 |
**Basic Usage**
|
| 59 |
|
|
@@ -63,6 +98,28 @@ cd example
|
|
| 63 |
bash infer.sh
|
| 64 |
```
|
| 65 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 66 |
## **Demos**
|
| 67 |
|
| 68 |
Here are some demos generated by Spark-TTS using zero-shot voice cloning. For more demos, visit our [demo page](https://spark-tts.github.io/).
|
|
|
|
| 30 |
- **Simplicity and Efficiency**: Built entirely on Qwen2.5, Spark-TTS eliminates the need for additional generation models like flow matching. Instead of relying on separate models to generate acoustic features, it directly reconstructs audio from the code predicted by the LLM. This approach streamlines the process, improving efficiency and reducing complexity.
|
| 31 |
- **High-Quality Voice Cloning**: Supports zero-shot voice cloning, which means it can replicate a speaker's voice even without specific training data for that voice. This is ideal for cross-lingual and code-switching scenarios, allowing for seamless transitions between languages and voices without requiring separate training for each one.
|
| 32 |
- **Bilingual Support**: Supports both Chinese and English, and is capable of zero-shot voice cloning for cross-lingual and code-switching scenarios, enabling the model to synthesize speech in multiple languages with high naturalness and accuracy.
|
| 33 |
+
- **Controllable Speech Generation**: Supports creating virtual speakers by adjusting parameters such as gender, pitch, and speaking rate.
|
| 34 |
+
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
<table align="center">
|
| 38 |
+
<tr>
|
| 39 |
+
<td align="center"><b>Inference Overview of Voice Cloning</b><br><img src="src/figures/infer_voice_cloning.png" width="80%" /></td>
|
| 40 |
+
</tr>
|
| 41 |
+
<tr>
|
| 42 |
+
<td align="center"><b>Inference Overview of Controlled Generation</b><br><img src="src/figures/infer_control.png" width="80%" /></td>
|
| 43 |
+
</tr>
|
| 44 |
+
</table>
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
## To-Do List
|
| 48 |
+
|
| 49 |
+
- [ ] Release the Spark-TTS paper.
|
| 50 |
+
- [ ] Release the training code.
|
| 51 |
+
- [ ] Release the training dataset, VoxBox.
|
| 52 |
+
|
| 53 |
|
| 54 |
## Install
|
| 55 |
**Clone and Install**
|
|
|
|
| 73 |
|
| 74 |
**Model Download**
|
| 75 |
|
| 76 |
+
Download via python:
|
| 77 |
+
```python
|
| 78 |
+
from huggingface_hub import snapshot_download
|
| 79 |
+
|
| 80 |
+
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
Download via git clone:
|
| 84 |
+
```sh
|
| 85 |
+
mkdir -p pretrained_models
|
| 86 |
+
|
| 87 |
+
# Make sure you have git-lfs installed (https://git-lfs.com)
|
| 88 |
+
git lfs install
|
| 89 |
+
|
| 90 |
+
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
|
| 91 |
+
```
|
| 92 |
|
| 93 |
**Basic Usage**
|
| 94 |
|
|
|
|
| 98 |
bash infer.sh
|
| 99 |
```
|
| 100 |
|
| 101 |
+
Alternatively, you can directly execute the following command in the command line to perform inference:
|
| 102 |
+
|
| 103 |
+
``` sh
|
| 104 |
+
python -m cli.inference \
|
| 105 |
+
--text "text to synthesis." \
|
| 106 |
+
--device 0 \
|
| 107 |
+
--save_dir "path/to/save/audio" \
|
| 108 |
+
--model_dir pretrained_models/Spark-TTS-0.5B \
|
| 109 |
+
--prompt_text "transcript of the prompt audio" \
|
| 110 |
+
--prompt_speech_path "path/to/prompt_audio"
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
**UI Usage**
|
| 114 |
+
|
| 115 |
+
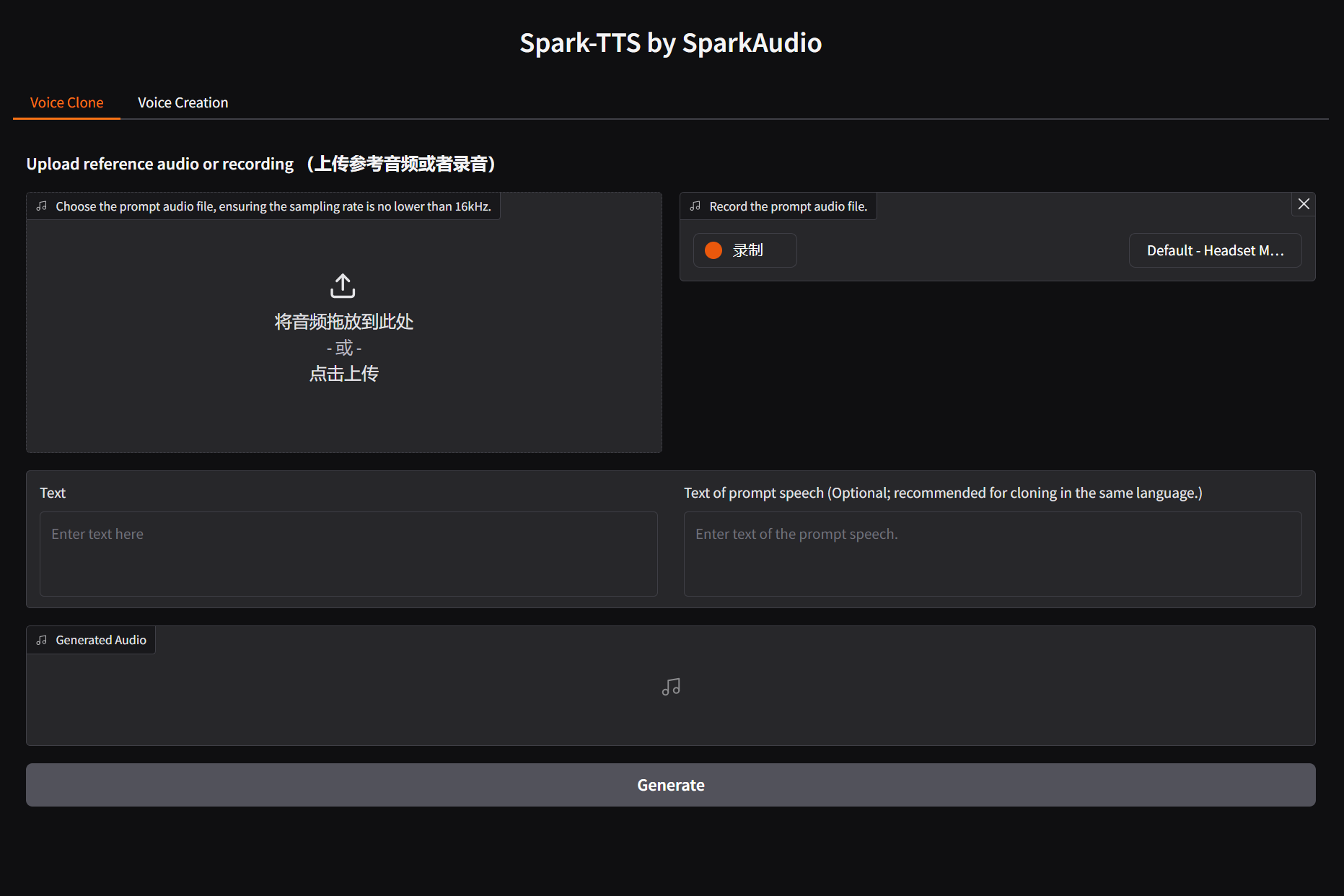
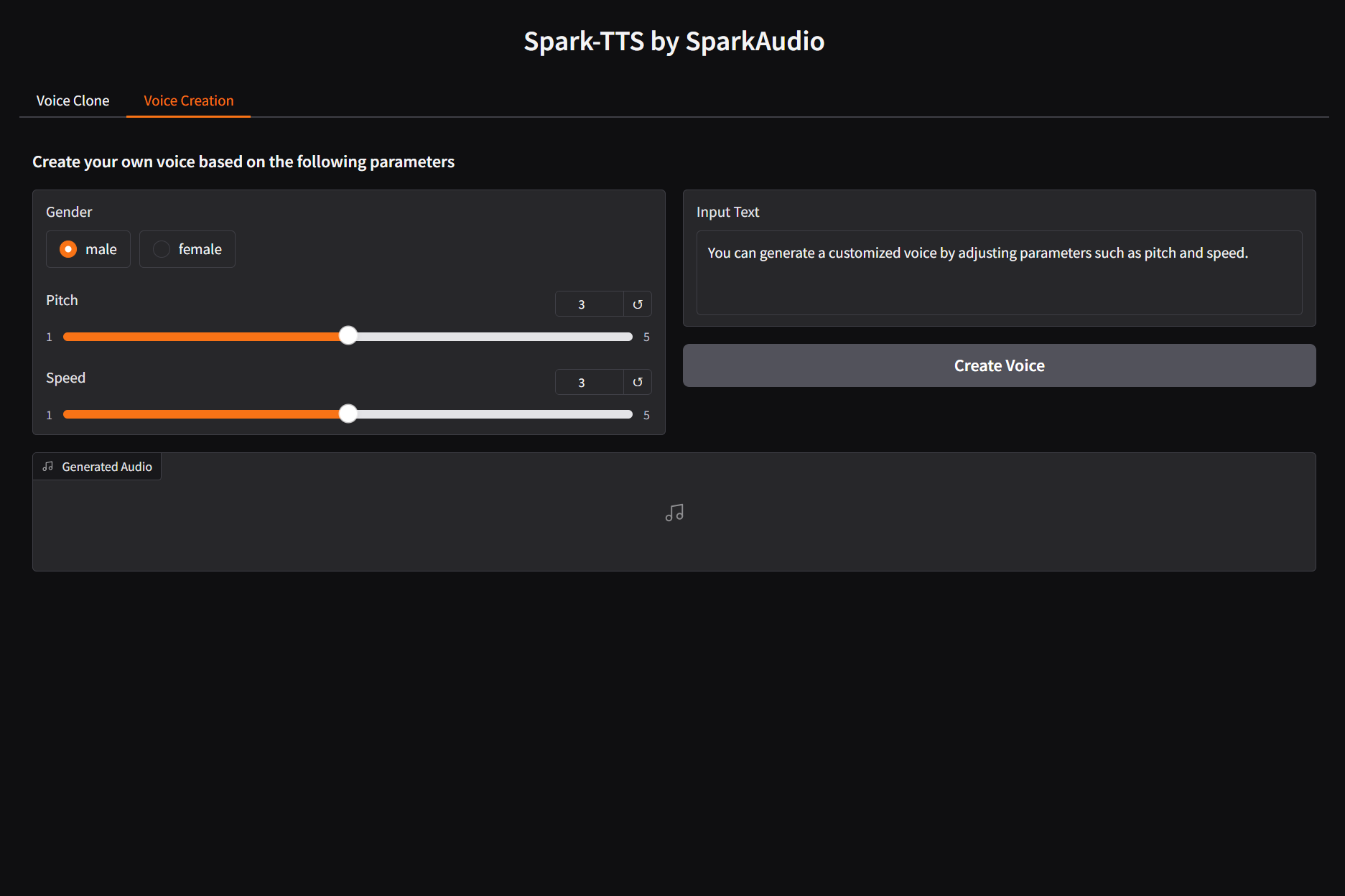
You can start the UI interface by running `python webui.py`, which allows you to perform Voice Cloning and Voice Creation. Voice Cloning supports uploading reference audio or directly recording the audio.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
| **Voice Cloning** | **Voice Creation** |
|
| 119 |
+
|:-------------------:|:-------------------:|
|
| 120 |
+
|  |  |
|
| 121 |
+
|
| 122 |
+
|
| 123 |
## **Demos**
|
| 124 |
|
| 125 |
Here are some demos generated by Spark-TTS using zero-shot voice cloning. For more demos, visit our [demo page](https://spark-tts.github.io/).
|
example/infer.sh
CHANGED
|
@@ -35,7 +35,7 @@ cd "$root_dir" || exit
|
|
| 35 |
|
| 36 |
source sparktts/utils/parse_options.sh
|
| 37 |
|
| 38 |
-
# Run inference
|
| 39 |
python -m cli.inference \
|
| 40 |
--text "${text}" \
|
| 41 |
--device "${device}" \
|
|
|
|
| 35 |
|
| 36 |
source sparktts/utils/parse_options.sh
|
| 37 |
|
| 38 |
+
# Run inference
|
| 39 |
python -m cli.inference \
|
| 40 |
--text "${text}" \
|
| 41 |
--device "${device}" \
|
src/figures/gradio_TTS.png
ADDED
|
src/figures/gradio_control.png
ADDED
|
src/figures/infer_control.png
ADDED

|
src/figures/infer_voice_cloning.png
ADDED

|