
File size: 23,405 Bytes
660379f 73c46b8 af2b4b5 3b8ef86 d609877 660379f af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 effad5d 24ce340 effad5d af2b4b5 effad5d af2b4b5 effad5d af2b4b5 24ce340 3fef804 af2b4b5 3fef804 24ce340 3fef804 af2b4b5 3fef804 af2b4b5 3fef804 af2b4b5 3fef804 af2b4b5 3fef804 af2b4b5 e68e2a4 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 af2b4b5 24ce340 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 |
---
library_name: transformers
base_model: tiiuae/falcon-7b-instruct
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- search-queries
- instruct-fine-tuned
- search-queries-parser
- zero-shot
- llm
- falcon
inference:
parameters:
temperature: 0.05
do_sample: False
---
# Model Card for the Query Parser LLM using Falcon-7B-Instruct
EmbeddingStudio is the [open-source framework](https://github.com/EulerSearch/embedding_studio/tree/main), that allows you transform a joint "Embedding Model + Vector DB" into
a full-cycle search engine: collect clickstream -> improve search experience-> adapt embedding model and repeat out of the box.
It's a highly rare case when a company will use unstructured search as is. And by searching `brick red houses san francisco area for april`
user definitely wants to find some houses in San Francisco for a month-long rent in April, and then maybe brick-red houses.
Unfortunately, for the 15th January 2024 there is no such accurate embedding model. So, companies need to mix structured and unstructured search.
The very first step of mixing it - to parse a search query. Usual approaches are:
* Implement a bunch of rules, regexps, or grammar parsers (like [NLTK grammar parser](https://www.nltk.org/howto/grammar.html)).
* Collect search queries and to annotate some dataset for NER task.
It takes some time to do, but at the end you can get controllable and very accurate query parser.
EmbeddingStudio team decided to dive into LLM instruct fine-tuning for `Zero-Shot query parsing` task
to close the first gap while a company doesn't have any rules and data being collected, or even eliminate exhausted rules implementation, but in the future.
The main idea is to align an LLM to being to parse short search queries knowing just a company market and a schema of search filters. Moreover, being oriented on applied NLP,
we are trying to serve only light-weight LLMs a.k.a `not heavier than 7B parameters`.
## Model Details
### Model Description
This is only [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) aligned to follow instructions like:
```markdown
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: Logistics and Supply Chain Management
#### Schema: ```[{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Monday", "Wednesday", "Friday", "Thursday", "Monday", "Tuesday"], "Enum": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["January", "June", "December"], "Enum": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]```
#### Query: Which logistics companies in the US have a perfect 5.0 rating ?
### Response:
[{"Value": "Which logistics companies in the US have a perfect 5.0 rating?", "Name": "Correct"}, {"Name": "Customer_Ratings.Exact_Rating", "Value": 5.0}, {"Name": "Destination_Country.Country_Code", "Value": "US"}]
```
**Important:** Additionally, we are trying to fine-tune the Large Language Model (LLM) to not only parse unstructured search queries but also to correct spelling.
- **Developed by EmbeddingStudio team:**
* Aleksandr Iudaev [[LinkedIn](https://www.linkedin.com/in/alexanderyudaev/)] [[Email](mailto:[email protected])]
* Andrei Kostin [[LinkedIn](https://www.linkedin.com/in/andrey-kostin/)] [[Email](mailto:[email protected])]
* ML Doom [AI Assistant]
- **Funded by EmbeddingStudio team**
- **Model type:** Instruct Fine-Tuned Large Language Model
- **Model task:** Zero-shot search query parsing
- **Language(s) (NLP):** English
- **License:** apache-2.0
- **Finetuned from model:** [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct)
- **!Maximal Length Size:** we used 1024 for fine-tuning, this is highly different from the original model `max_seq_length = 2048`
- **Tuning Epochs:** 3 for now, but will be more later.
**Disclaimer:** As a small startup, this direction forms a part of our Minimum Viable Product (MVP). It's more of
an attempt to test the 'product-market fit' rather than a well-structured scientific endeavor. Once we check it and go with a round, we definitely will:
* Curating a specific dataset for more precise analysis.
* Exploring various approaches and Large Language Models (LLMs) to identify the most effective solution.
* Publishing a detailed paper to ensure our findings and methodologies can be thoroughly reviewed and verified.
We acknowledge the complexity involved in utilizing Large Language Models, particularly in the context
of `Zero-Shot search query parsing` and `AI Alignment`. Given the intricate nature of this technology, we emphasize the importance of rigorous verification.
Until our work is thoroughly reviewed, we recommend being cautious and critical of the results.
### Model Sources
- **Repository:** code of inference the model will be [here](https://github.com/EulerSearch/embedding_studio/tree/main)
- **Paper:** Work In Progress
- **Demo:** Work In Progress
## Uses
We strongly recommend only the direct usage of this fine-tuned version of [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct):
* Zero-shot Search Query Parsing with porived company market name and filters schema
* Search Query Spell Correction
For any other needs the behaviour of the model in unpredictable, please utilize the [original mode](https://huggingface.co/tiiuae/falcon-7b-instruct) or fine-tune your own.
### Instruction format
```markdown
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {your_company_category}
#### Schema: ```{filters_schema}```
#### Query: {query}
### Response:
```
Filters schema is JSON-readable line in the format (we highly recommend you to use it):
List of filters (dict):
* Name - name of filter (better to be meaningful).
* Representations - list of possible filter formats (dict):
* Name - name of representation (better to be meaningful).
* Type - python base type (int, float, str, bool).
* Examples - list of examples.
* Enum - if a representation is enumeration, provide a list of possible values, LLM should map parsed value into this list.
* Pattern - if a representation is pattern-like (datetime, regexp, etc.) provide a pattern text in any format.
Example:
```json
[{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Monday", "Wednesday", "Friday", "Thursday", "Monday", "Tuesday"], "Enum": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["January", "June", "December"], "Enum": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]
```
As the result, response will be JSON-readable line in the format:
```json
[{"Value": "Corrected search phrase", "Name": "Correct"}, {"Name": "filter-name.representation", "Value": "some-value"}]
```
Field and representation names will be aligned with the provided schema. Example:
```json
[{"Value": "Which logistics companies in the US have a perfect 5.0 rating?", "Name": "Correct"}, {"Name": "Customer_Ratings.Exact_Rating", "Value": 5.0}, {"Name": "Destination_Country.Country_Code", "Value": "US"}]
```
Used for fine-tuning `system` phrases:
```python
[
"Expert at Deconstructing Search Queries",
"Master in Query Analysis",
"Premier Search Query Interpreter",
"Advanced Search Query Decoder",
"Search Query Parsing Genius",
"Search Query Parsing Wizard",
"Unrivaled Query Parsing Mechanism",
"Search Query Parsing Virtuoso",
"Query Parsing Maestro",
"Ace of Search Query Structuring"
]
```
Used for fine-tuning `instruction` phrases:
```python
[
"Convert queries to JSON, align with schema, ensure correct spelling.",
"Analyze and structure queries in JSON, maintain schema, check spelling.",
"Organize queries in JSON, adhere to schema, verify spelling.",
"Decode queries to JSON, follow schema, correct spelling.",
"Parse queries to JSON, match schema, spell correctly.",
"Transform queries to structured JSON, align with schema and spelling.",
"Restructure queries in JSON, comply with schema, accurate spelling.",
"Rearrange queries in JSON, strict schema adherence, maintain spelling.",
"Harmonize queries with JSON schema, ensure spelling accuracy.",
"Efficient JSON conversion of queries, schema compliance, correct spelling."
]
```
### Direct Use
```python
import json
from json import JSONDecodeError
from transformers import AutoTokenizer, AutoModelForCausalLM
INSTRUCTION_TEMPLATE = """
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {0}
#### Schema: ```{1}```
#### Query: {2}
### Response:
"""
def parse(
query: str,
company_category: str,
filter_schema: dict,
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer
):
input_text = INSTRUCTION_TEMPLATE.format(
company_category,
json.dumps(filter_schema),
query
)
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# Generating text
output = model.generate(input_ids.to('cuda'),
max_new_tokens=1024,
do_sample=True,
temperature=0.05,
pad_token_id=50256
)
try:
parsed = json.loads(tokenizer.decode(output[0], skip_special_tokens=True).split('## Response:\n')[-1])
except JSONDecodeError as e:
parsed = dict()
return parsed
```
## Bias, Risks, and Limitations
### Bias
Again, this model was fine-tuned for following the zero-shot query parsing instructions.
So, all ethical biases are inherited by the original model.
Model was fine-tuned to be able to work with the unknown company domain and filters schema. But, can be better with the training company categories:
Educational Institutions, Job Recruitment Agencies, Banking Services, Investment Services, Insurance Services, Financial Planning and Advisory, Credit Services, Payment Processing, Mortgage and Real Estate Services, Taxation Services, Risk Management and Compliance, Digital and Mobile Banking, Retail Stores (Online and Offline), Automotive Dealerships, Restaurants and Food Delivery Services, Entertainment and Media Platforms, Government Services, Travelers and Consumers, Logistics and Supply Chain Management, Customer Support Services, Market Research Firms, Mobile App Development, Game Development, Cloud Computing Services, Data Analytics and Business Intelligence, Cybersecurity Software, User Interface/User Experience Design, Internet of Things (IoT) Development, Project Management Tools, Version Control Systems, Continuous Integration/Continuous Deployment, Issue Tracking and Bug Reporting, Collaborative Development Environments, Team Communication and Chat Tools, Task and Time Management, Customer Support and Feedback, Cloud-based Development Environments, Image Stock Platforms, Video Hosting and Portals, Social Networks, Professional Social Networks, Dating Apps
### Risks and Limitations
Known limitations:
1. Can add extra spaces or remove spaces: `1-2` -> `1 - 2`.
2. Can add extra words: `5` -> `5 years`.
3. Can not differentiate between `<>=` and theirs HTML versions `<`, `>`, `&eq;`.
4. Bad with abbreviations.
5. Can add extra `.0` for floats and integers.
6. Can add extra `0` or remove `0` for integers with a char postfix: `10M` -> `1m`.
7. Can hallucinate with integers. For the case like `list of positions exactly 7 openings available` result can be
`{'Name': 'Job_Type.Exact_Match', 'Value': 'Full Time'}`.
8. We fine-tuned this model with max sequence length = 1024, so it may happen that response will not be JSON-readable.
The list will be extended in the future.
### Recommendations
1. We used synthetic data for the first version of this model. So, we suggest you to precisely test this model on your company's domain, even it's in the list.
2. Use meaningful names for filters and theirs representations.
3. Provide examples for each representation.
4. Try to be compact, model was fine-tuned with max sequence length equal 1024.
5. During the generation use greedy strategy with tempertature 0.05.
6. The result will be better if you align a filters schema with a schema type of the training data.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
MODEL_ID = 'EmbeddingStudio/query-parser-falcon-7b-instruct'
```
Initialize tokenizer:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
add_prefix_space=True,
use_fast=False,
)
```
Initialize model:
```python
import torch
from peft import LoraConfig
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
load_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
device_map = {"": 0}
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map=device_map,
torch_dtype=torch.float16
)
```
Use for parsing:
```python
import json
from json import JSONDecodeError
INSTRUCTION_TEMPLATE = """
### System: Master in Query Analysis
### Instruction: Organize queries in JSON, adhere to schema, verify spelling.
#### Category: {0}
#### Schema: ```{1}```
#### Query: {2}
### Response:
"""
def parse(
query: str,
company_category: str,
filter_schema: dict,
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer
):
input_text = INSTRUCTION_TEMPLATE.format(
company_category,
json.dumps(filter_schema),
query
)
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# Generating text
output = model.generate(input_ids.to('cuda'),
max_new_tokens=1024,
do_sample=True,
temperature=0.05,
pad_token_id=50256
)
try:
parsed = json.loads(tokenizer.decode(output[0], skip_special_tokens=True).split('## Response:\n')[-1])
except JSONDecodeError as e:
parsed = dict()
return parsed
category = 'Logistics and Supply Chain Management'
query = 'Which logistics companies in the US have a perfect 5.0 rating ?'
schema = [{"Name": "Customer_Ratings", "Representations": [{"Name": "Exact_Rating", "Type": "float", "Examples": [4.5, 3.2, 5.0, "4.5", "Unstructured"]}, {"Name": "Minimum_Rating", "Type": "float", "Examples": [4.0, 3.0, 5.0, "4.5"]}, {"Name": "Star_Rating", "Type": "int", "Examples": [4, 3, 5], "Enum": [1, 2, 3, 4, 5]}]}, {"Name": "Date", "Representations": [{"Name": "Day_Month_Year", "Type": "str", "Examples": ["01.01.2024", "15.06.2023", "31.12.2022", "25.12.2021", "20.07.2024", "15.06.2023"], "Pattern": "dd.mm.YYYY"}, {"Name": "Day_Name", "Type": "str", "Examples": ["Monday", "Wednesday", "Friday", "Thursday", "Monday", "Tuesday"], "Enum": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]}]}, {"Name": "Date_Period", "Representations": [{"Name": "Specific_Period", "Type": "str", "Examples": ["01.01.2024 - 31.01.2024", "01.06.2023 - 30.06.2023", "01.12.2022 - 31.12.2022"], "Pattern": "dd.mm.YYYY - dd.mm.YYYY"}, {"Name": "Month", "Type": "str", "Examples": ["January", "June", "December"], "Enum": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]}, {"Name": "Quarter", "Type": "str", "Examples": ["Q1", "Q2", "Q3"], "Enum": ["Q1", "Q2", "Q3", "Q4"]}, {"Name": "Season", "Type": "str", "Examples": ["Winter", "Summer", "Autumn"], "Enum": ["Winter", "Spring", "Summer", "Autumn"]}]}, {"Name": "Destination_Country", "Representations": [{"Name": "Country_Name", "Type": "str", "Examples": ["United States", "Germany", "China"]}, {"Name": "Country_Code", "Type": "str", "Examples": ["US", "DE", "CN"]}, {"Name": "Country_Abbreviation", "Type": "str", "Examples": ["USA", "GER", "CHN"]}]}]
output = parse(query, category, schema)
print(output)
# [out]: [{"Value": "Which logistics companies in the US have a perfect 5.0 rating?", "Name": "Correct"}, {"Name": "Customer_Ratings.Exact_Rating", "Value": 5.0}, {"Name": "Destination_Country.Country_Code", "Value": "US"}]
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** NVIDIA Tesla V100
- **Hours used:** 72
- **Cloud Provider:** Google Cloud
- **Compute Region:** us-west-1
- **Carbon Emitted:** 6.48
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
* Python 3.9+
* CUDA 11.7.1
* NVIDIA [Compatible Drivers](https://www.nvidia.com/download/find.aspx)
* Torch 2.0.0
## More Information / About us
EmbeddingStudio is an innovative open-source framework designed to seamlessly convert a combined
"Embedding Model + Vector DB" into a comprehensive search engine. With built-in functionalities for
clickstream collection, continuous improvement of search experiences, and automatic adaptation of
the embedding model, it offers an out-of-the-box solution for a full-cycle search engine.
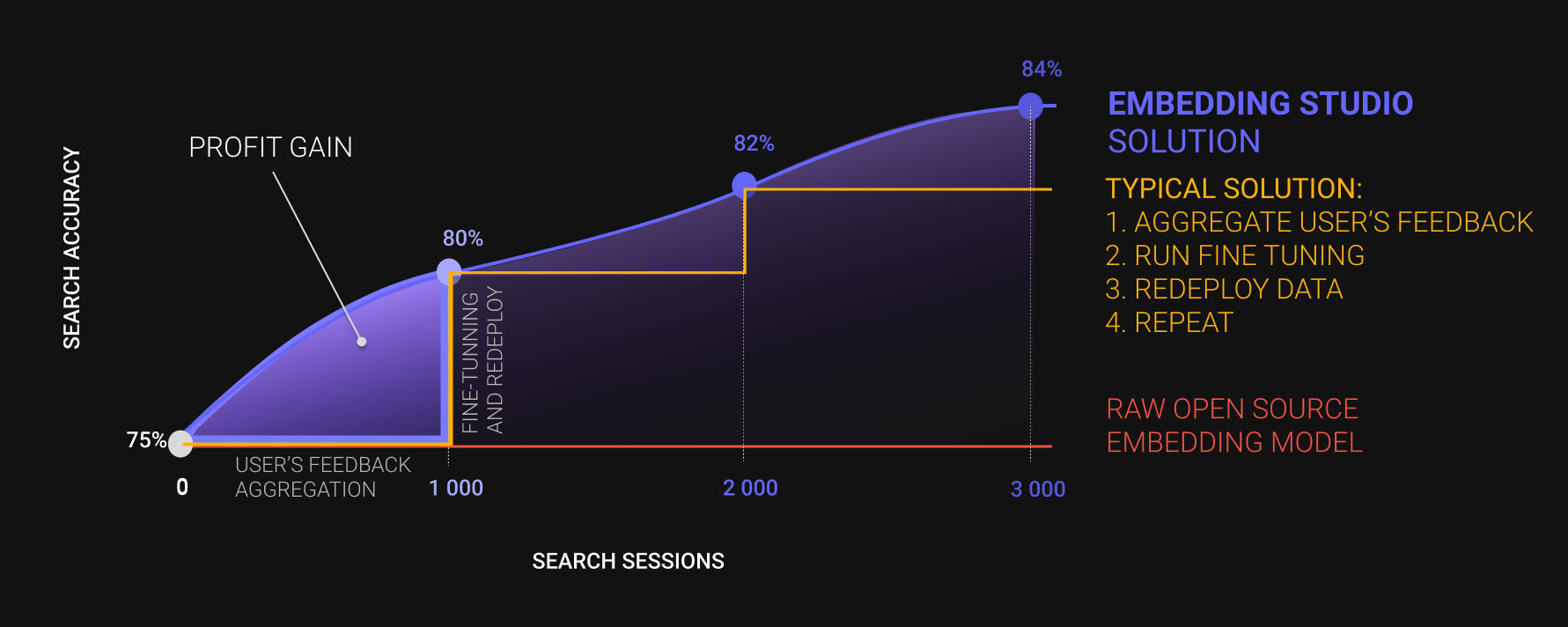
### Features
1. 🔄 Turn your vector database into a full-cycle search engine
2. 🖱️ Collect users feedback like clickstream
3. 🚀 (*) Improve search experience on-the-fly without frustrating wait times
4. 📊 (*) Monitor your search quality
5. 🎯 Improve your embedding model through an iterative metric fine-tuning procedure
6. 🆕 (*) Use the new version of the embedding model for inference
(*) - features in development
EmbeddingStudio is highly customizable, so you can bring your own:
1. Data source
2. Vector database
3. Clickstream database
4. Embedding model
For more details visit [GitHub Repo](https://github.com/EulerSearch/embedding_studio/tree/main).
## Model Card Authors and Contact
* Aleksandr Iudaev [[LinkedIn](https://www.linkedin.com/in/alexanderyudaev/)] [[Email](mailto:[email protected])]
* Andrei Kostin [[LinkedIn](https://www.linkedin.com/in/andrey-kostin/)] [[Email](mailto:[email protected])]
* ML Doom [AI Assistant]
### Framework versions
- PEFT 0.5.0
- Datasets 2.16.1
- BitsAndBytes 0.41.0
- PyTorch 2.0.0
- Transformers 4.36.2
- TRL 0.7.7 |